How GFS works
Google File System is a distributed storage systems designed for high performance, fault tolerance, and high availability while running on inexpensive commodity hardware. We have seen many distributed systems such as HDFS, Ceph, S3 used in industry. GFS is the first distributed storage system used in industry. It not only got the basic ideas of distribution, sharding, fault-tolerance but also scaled hugely and created on real-world experience. It successfully applied the single master and weak consistency.
Despite the simplicity of the whole GFS architecture, the GFS paper is not hard to read. If you understand it well, you will know how a simple distributed storage systems works. It can also be your first step to learning distributed systems.
Architecture
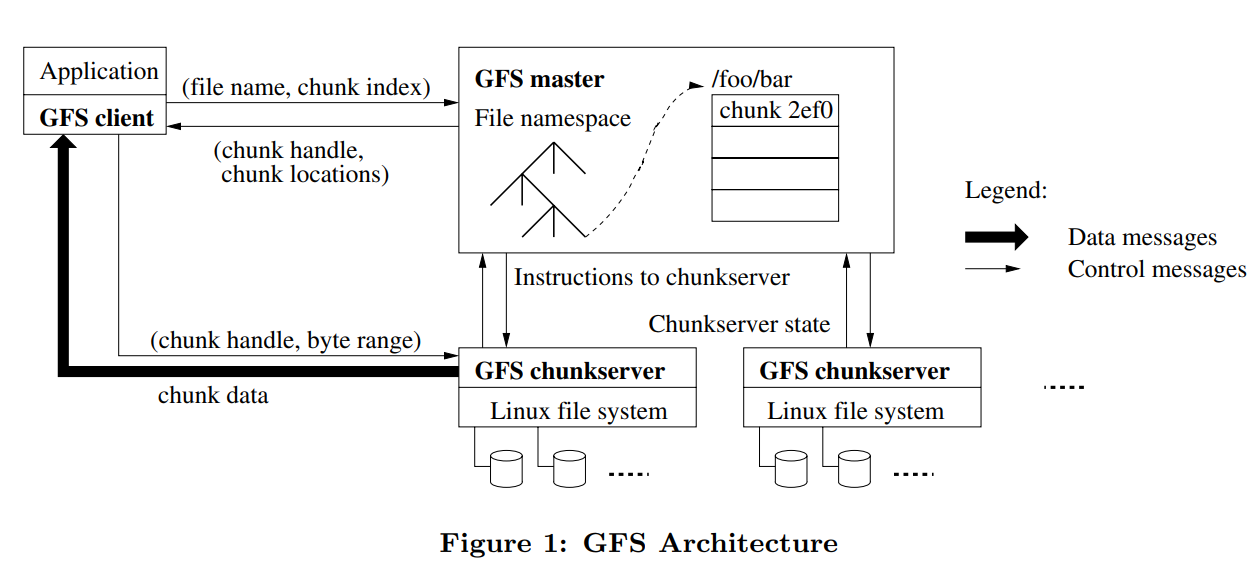
GFS has three major components: Client, Master and Chunkserver. GFS split a file into multiple chunks and saved it into Chunkserver. Master stored metadata in memory, which contains each chunk's location information. Metadata operation uses Binlog and Checkpoint for backup and accident crash resuming.
When client writes a file to GFS, the client first asks Master about which Chunkserver can store this file. The Master will return the metadata to the client. The client split the file into chunks and send them to Chunkserver that metadata pointed to.
The read processing is the same as writing. Get the metadata, then read each chunk from Chunkserver and finally combine chunks with a file.
For figuring out the entire architecture, you just need to know the relationship among Client, Master and Chunkserver.
Consistency model
Data Consistency is the key in distributed storage systems. It affected the entire architecture design. For understanding the consistency model well, we must know what is the exact consistency problem in the system, why is the key problem, how does it affect the entire architecture design.
Consistency problem is the same as a race condition in the operating system. If we access a variable via different threads, we might get different values at different times.
A----set x = 1
B----set x = 2
C----get x = ?
C----get x = ?
Thread A&B set x concurrently, C might get different values at different times.
The race condition gets complicated when it occurred in distributed systems.
Suppose A and B are two different nodes, we may set x in A or B. And C gets the value via A or B. The ideal solution is no matter how C gets x via A or B, it always gets the same value. How to implement it?
A----set x = 1
B----set x = 2
C----get x = ? in A
C----get x = ? in B
If x is concurrently set in two different nodes, we must handle these two problems:
- how to guarantee the order of writing in different nodes?
- how to prevent the C read x via A or B return the different values?
First of all, there is no such solution that can handle the order of writing perfectly. When we set x in different nodes at different times, we cannot sync the order. Because the order is based on time, there is no such way to sync time precisely between two nodes. The network communication itself has imprecise latency. When we want data stored safely. We don't have other choices, we must write a copy in different ways(such as datacenter, rack, node, disk). The replica strategy is the root of the consistent problem. If data has been written in different nodes, we cannot avoid the inconsistent problem(question 2). As you know with the 'imprecise latency', we don't have the precise mechanism to sync two nodes. If we want to perform the consistent problem, we should reduce the writing in one node and then sync the replica to the other nodes. That's why GFS designed chunkserver as primary and secondaries.
GFS consistency guarantees
The primary receives the data first and then sends it to other secondaries. This mechanism makes the consistency problem in GFS became a single node concurrency problem. The entire Architecture served this simple consistency model. For performing the consistency problem, GFS guaranteed some consistency mutations.
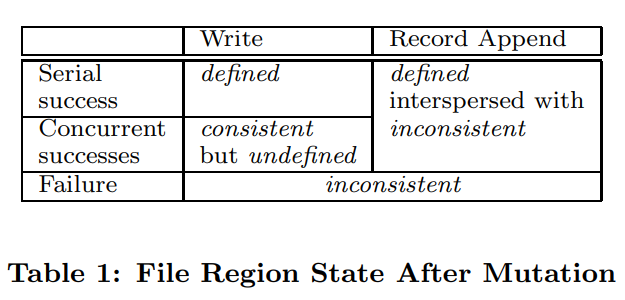
Consistent: all clients will always see the same data.
Defined: A region is defined after a file data mutation if it is consistent and clients will see what the mutation writes in its entirety(implication consistent)
Undefined: client didn't know which mutation has written, but the data is consistent.
Inconsistent: data is broken, which cannot be useful.
GFS has two kinds of concurrent writing: write and record append. They have different guarantees. The Record append is simple. If two clients append a record currently, the order is defined. It will be written one by one.
x=1
x=2
x=3
x=4
Record append is the simplest way to ensure the data has been written consistently. When one client writes a chunk, the chunk will be locked, the other client's writing would be arranged the next chunk. GFS keeps every appending chunk written at least once atomically. When multiple clients write a chunk concurrently, at least once atomically keeps the record append as multiple-producer/single-consumer.
We can see the steps when C wants to do a "record append"? (from MIT6.824)
- C asks M about file's last chunk
- if M sees chunk has no primary (or lease expired): 2a. if no chunkservers w/ latest version #, error 2b. pick primary P and secondaries from those w/ latest version # 2c. increment version #, write to log on disk 2d. tell P and secondaries who they are, and new version # 2e. replicas write new version # to disk
- M tells C the primary and secondaries
- C sends data to all (write in cache), waits
- C tells P to append
- P checks that lease hasn't expired, and chunk has space
- P picks an offset (at end of chunk)
- P writes chunk file (a Linux file)
- P tells each secondary the offset, tells to append to chunk file
- P waits for all secondaries to reply, or timeout secondary can reply "error" e.g. out of disk space
- P tells C "ok" or "error"
- C retries from start if error
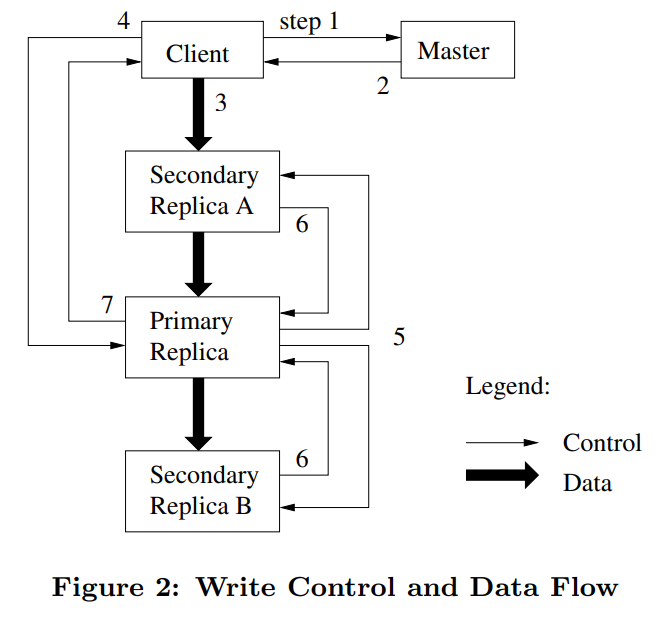
The above steps send data to Primary and then send to Secondaries. It first cached data in memory and then write to disk, the writing has been separated into two steps:
- data cached in LRU mechanism.
- receive the disk write request, then start to write on disk.
Primary has the lease that determined the data order for other secondaries. This writing mechanism also reduces disk I/O pressure.
How about the normal write?
It's the same as the record append. The primary chunkserver and two secondaries must write in the same order. When two concurrent clients write data, the order of writing will not guarantee, which is called 'undefined' in GFS. But it will have been written consistently on different nodes. (undefined but consistent).
If one of three chunks has written failed, how to handle it?
Rewrite the three replicas to another chunk. The old three chunks will be reclaimed by garbage collection scanner.
What are the steps when client C wants to read a file? (from MIT6.824)
- C sends filename and offset to master M (if not cached)
- M finds chunk handle for that offset
- M replies with list of chunkservers only those with latest version
- C caches handle + chunkserver list
- C sends request to nearest chunkserver chunk handle, offset
- chunk server reads from chunk file on disk, returns
How lease works in GFS
Lease means two nodes make a promise in a period of time. If I give you a lease, I would promise the data would not be changed in the given time. GFS uses lease to maintain an inconsistent mutation order across replicas, if a master grant a lease to a primary chunkserver, even the network fails, master and primary still wait until the lease expires.
high availability
Each chunk(three replicas) is stored on multiple chunkservers. The chunk version number can be used to check the stale chunk fast. When a chunk was stale or broken, the master would copy from another replica to replace it. Both chunkserver and master are designed for resuming fast. When a chunkserver crashed, it can be restarted or start a new chunkserver. Chunkserver will report its chunk information after connecting to master. Master can detect the stale chunks with the version number. A new empty chunkserver will be filled with chunks that are copied from other replicas.
When a master has crashed, it can be resumed instantly. Master can recover by loading the latest checkpoint from the local disk and replaying only the limited number of log records after that. If a master can not restart again, it will switch to a shadow master for read-only. Switch a new master is fast via DNS. GFS doesn't depend on master so heavily. Client cache the metadata for a lease time, and primary didn't communicate with master so often. Even a master has crashed, the client and chunkserver can still work in a short time. It gives time to master for resuming. That's why GFS can apply the single master in production environment.
Garbage collection
When master needs to delete a file, it will be renamed to a hidden file name. This hidden file can be alive for a period of time, until then the file can be read or recovered. Master will scan regularly to remove the file and metadata permanently. This delay removing has the advantages of eager deletion:
- it can serve the failed operation.
- it can be running in the background, the high consuming activities will be running in free time.
- given chance for accidental deletion.
The only disadvantage is the storage space will not reclaim immediately.
Extra questions
For understanding GFS well, I copied some questions from MIT6.824 lecture and tried to answer them.
Why big chunks?
Google has many big files that need to store, splitting files into big chunks can reduce I/O pressure and the size of metadata.
Why a log? and checkpoint?
The single Master has to save the metadata safely, binlog is a simple way to save the metadata safely. Use checkpoint can restore the crashed master instantly.
How does the master know what chunkservers have a given chunk?
Chunkserver will report its chunk information to master, when it started and send the heartbeat package to master.
What if an appending client fails at an awkward moment? Is there an awkward moment?
It doesn't need to much care, just append it again.
c1 c2 c3
a a a
b b b
c c x //broken written
d d d
c c c //append again
What if the appending client has cached a stale (wrong) primary?
It should wait a lease time to expire the stale primary or request master again.
What if the reading client has cached a stale secondary list?
The stale secondary will return stale chunks, but the client can detect it.
Could a master crash+reboot cause it to forget about the file? Or forget what chunkservers hold the relevant chunk?
When a master restart, it will restore the state from binlog, and the connected chunkserver will report their chunk information.
Two clients do record append at exactly the same time. Will they overwrite each others' records?
No, They will not. Because the record append has at least once atomic mechanism.
Suppose one secondary never hears the append command from the primary. What if reading client reads from that secondary?
The client would never read from this secondary, because no data has been written successfully.
What if the primary crashes before sending append to all secondaries? Could a secondary that didn't see the append be chosen as the new primary?
Yes. According the appending process, the data write into memory first then written to disk. If primary crashed, the data will be removed from memory.
Chunkserver S4 with an old stale copy of chunk is offline. Primary and all live secondaries crash. S4 comes back to life (before primary and secondaries). Will master choose S4 (with stale chunk) as primary? Better to have primary with stale data, or no replicas at all?
Yes, S4 would be primary. But its stale data will be scanned by the master. After the old primary is restarted, the stale chunk can be rewritten from other replicas.
What should a primary do if a secondary always fails writes? e.g. dead, or out of disk space, or disk has broken. Should the primary drop secondary from set of secondaries? And then return success to client appends? Or should the primary keep sending ops, and having them fail, and thus fail every client write request?
The primary would keep sending ops, and clients would choose another set to write. If a new server or disk has been chosen in the set, it will trigger the re-replica for rebalancing chunks.
What if primary S1 is alive and serving client requests, but network between master and S1 fails? "network partition" Will the master pick a new primary? Will there now be two primaries? So that the append goes to one primary, and the read to the other? Thus breaking the consistency guarantee? "split brain"
No. It doesn't break the consistency guarantee. The primary must serve on the lease time. After this time, a new primary would have been chosen.
If there's a partitioned primary serving client appends, and its lease expires, and the master picks a new primary, will the new primary have the latest data as updated by partitioned primary?
Yes, it has the latest data which was updated by the old primary. Because the lease can guarantee data consistency.
What if the master fails altogether. Will the replacement know everything the dead master knew? E.g. each chunk's version number? primary? lease expiry time?
The replacement should restore the information that the dead master knew, and the lease should still wait for the exact time for expiring.
Who/what decides the master is dead, and must be replaced? Could the master replicas ping the master, take over if no response?
The monitor decides the master is dead or not. It takes over the dead master, restart the master or switch to a shadow-master(read-only).
What happens if the entire building suffers a power failure? And then power is restored, and all servers reboot.
The master will restore its metadata, reconnect to chunkservers and reconstruct the entire system.
Is there any circumstance in which GFS will break the guarantee? answered by teacher
All master replicas permanently lose state (permanent disk failure). Could be worse: result will be "no answer", not "incorrect data". "fail-stop"
All chunkservers holding the chunk permanently lose disk content.
again, fail-stop; not the worse possible outcome
CPU, RAM, network, or disk yields an incorrect value.
checksum catches some cases, but not all
Time is not properly synchronized, so leases don't work out.
So multiple primaries, maybe write goes to one, read to the other.
What application-visible anomalous behavior does GFS allow?
Will all clients see the same file content?
Could one client see a record that another client doesn't see at all?
Will a client see the same content if it reads a file twice?
Will all clients see successfully appended records in the same order?
GFS is a weakly consistent system, writing may have inconsistent data. If clients have read the inconsistent data, the library code would help them to check the inconsistent data. According to the GFS consistency model, all clients should see the same content at different times. The inconsistent data should never return to the applications.
Will these anomalies cause trouble for applications? How about Map Reduce?
Inconsistent data is worse and completely unuseful and causes troubles for applications.