NSQ 简介
在一般的 HTTP 后台系统中如果使用大量使用同步 API 调用一个长时间的任务时会拖慢整个系统的承载能力。在流量不大的情况下,我们可以把利用像 Redis 这样的缓存系统自行设计一个简单 producer / consumer 模式的消息队列。做好这个组件我们需要考虑到的问题有:
1.多个线程抢占一个资源时加锁的问题。
2.保证每个消息都能执行一次。
3.保证这个组件不会因为突发流量高峰而宕机。
要解决这三个问题并不容易,如果需要大规模的任务处理,横向扩展,分布式,预防单点故障等一系列需要解决的问题并不少。这时候选用一个久经考验的消息队列系统是非常好的选择。
NSQ 是一个实时消息推送平台。它具有分布式,水平扩展,低延时,防止单点故障等特性。与类似 RubbitMQ, ZeroMQ 等分布式队列一样,主要用于解决异步高并发消息的推送与处理。与其他分布式队列不同的是,NSQ 没有类似 brokers 的中间节点,无中心的特性可以让它无缝添加一个节点。
按组件分类,NSQ 主要可以分为三大块,分别是:
nsqd (核心组件)用于接收与分发消息,处理通信协议。
nsqlookupd 用于查找并定位多个 nsqd,管理多个 nsqd 之间的拓扑信息。它不负责处理任何数据的传输与处理。
producer / consumer 消息的生产与发送者,这是用户功能具体实现的地方。每当一个消息由生产者发送到整个 NSQ 网络中,会有一个对应 consumer 负责与 NSQ 通信并处理这个消息。
下图是这三个组件之间的拓扑关系:
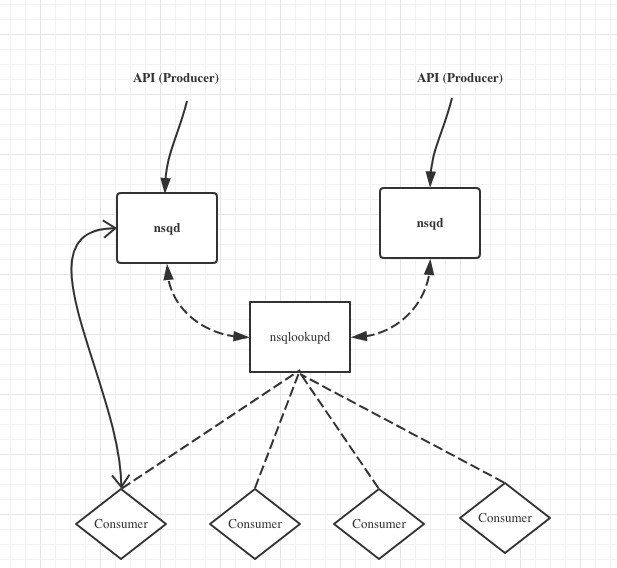
nsqlookupd 用于连接 consumer 和 nsqd,它作的工作类似于寻址,帮助 nsqd 找到对应的 consumer 处理消息。
在这里有个地方非常值得注意,就是 producer 没有通过 nsqlookupd 去找对应的对应的 nsq 节点发送消息。而是直接通过一个 nsqd 发送,这么设计的原因是:
- producer 只要负责把消息投递出去,系统的并发处理压力全在 consumer 这一端。再多的 producer 发消息都不会影响 consumer 的运行效率。
- 如果 producer 通过 nsqlookupd 寻址找 nsqd,会产生鸡生蛋蛋生鸡的问题。
- 配置更简单,横向扩展要更容易。
更多详细情参见这里。
基于发布/订阅模式,每个消息会属于一个 topic,每个 consumer 会订阅一个 topic 用来处理同一类的消息。每个 topic 会有一个对应的 channel (此 channel 非彼 channel)。为了防止堵塞,多个 consumer 可以共享一个 channel 来处理消息。如果一个 topic 经由多个 channel 发出去,那么这个 topic 相关的全部 messages 会经由 多个 channel 重复发送,这一点在使用时一定要注意。
另外就是 consumer 执行的任务注意幂等性,为了“保证每个任务都被执行一次”,就有可能会重复的发送消息或者任务执行失败后重试,在这样的条件下,每个任务执行的次数就有可能达到一次以上。